Parsing Appleworks and Clarisworks file formats
Over the past few years, when I have downtime, I sometimes like to reverse engineer abandoned file formats. It is kind of like working on a crossword puzzle with the bonus that any progress you make helps people out there who are trying to archive, index, or convert their old files.
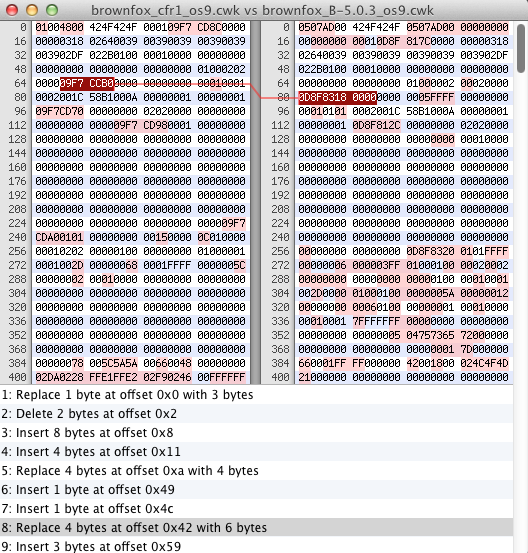
I’ve spent a lot of time trying to figure out file format for Appleworks and Clarisworks. My latest efforts have been to take a file, make a small change, then use Hex Fiend to compare what has changed in the binary format.
After years of off and on tinkering and documenting I finally wrote a basic parser for Appleworks and Clarisworks word processor files. I ‘believe’ this is the first free and open parser for this file format, even if it is ten years too late. I figured out a lot about the format, but it still has a long way to go. You can view my current documenting status here and download source for the parser on GitHub.
The parser so far can read:
- document version
- page size
- margins
- document content

From what I have seen, most people trying to read Appleworks documents only really care about the document content, but I am very close to figuring out how to parse:
- styles – (bold, italic, underline)
- footnotes
I may not touch it again for another year, but who knows.